
Life of Voyanticians – The Lazy Engineer
Oct 13, 2022
![]() Content Warning! This post includes some serious engineering terminology. Reader discretion is advised! 😉
Content Warning! This post includes some serious engineering terminology. Reader discretion is advised! 😉
“Being Lazy”
At Voyantic we value “lazy engineers”, a term that often is linked to efficiency in the engineering context. One key aspect of efficiency in software development is automation, and software engineers have been working with CI (continuous integration) / CD (continuous delivery) systems for eons to have their code automatically built, tested, and deployed. Typically these CI systems run neatly on the cloud, either self-hosted or as a service.

The same CI / CD practices are not nearly as widely adopted on the embedded side as those are on the server-side software. This was also true for Voyantic, but we have decided that there are no excuses not to have HW part of the CI cycle, especially when the other option is to do manual regression testing – ouch!
In this blog post, I’ll describe how we try to be lazy while leveraging automation in our development and testing practices.
Efficient Test Automation
4 Key aspects for efficient test automation
- Test triangle as a guideline
- Automate everything
- Fast feedback loop for development
- Reliable tests and automation
How these are applied at Voyantic
For those unfamiliar with the test triangle, it is best depicted by the following diagram.
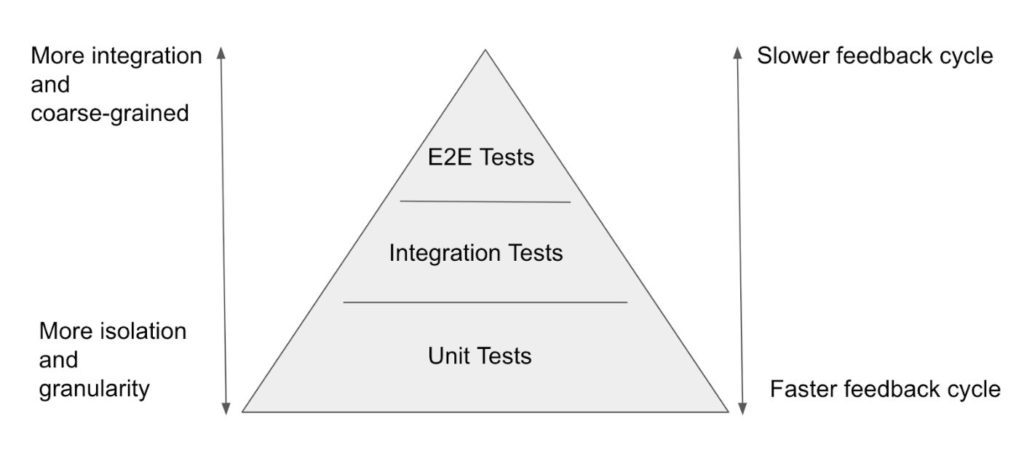
Lower-level tests are running faster and have the opportunity to test corner cases more easily but are run in isolation, without testing the interoperability of the code and components. Capability for rapid code changes requires fast test cycles. Pull request (PR) builds are running unit tests and integration tests to have that fast feedback cycle, typically within minutes, and covering both the fine-grained unit tests and integration tests ensuring interoperability.
Unit test definition always seems so clear until you realize that developers have vastly different unit sizes that they test. Our approach is to test code in isolation, one file/module/class at a time, and mock anything external. Truly testing just the unit.
At the integration test level, we prefer the real thing over mocks. Firmware changes are flashed to the device and tested using its API and cloud services are deployed and tested using their API. If a tested piece of a component depends on other services or hardware, then real hardware or deployed service is used instead of the mock. In some cases, it is not possible to avoid mocking or simulation but those are the exceptions that make the rule. Mocking is avoided for a couple of different reasons; 1. There is a significant amount of development and maintenance required to mock something. 2. Mock always fails to simulate the real thing perfectly, allowing bugs to go unnoticed.
End to End tests are gating software release and performed on a high level, simulating the end-user behavior, potentially having a long execution time. For example, we are using Playwright to test ReactJS-based Web UIs. This category includes also other long-running test types, like soak tests, where for example our Tagsurance 3 system is run for days without interruption to simulate its usage on the production line producing RFID tags. These types of tests will catch issues that only manifest over time, like a slow memory leak, data store efficiency with bigger data sets, overheating, etc.
Theory Meets the Hardware
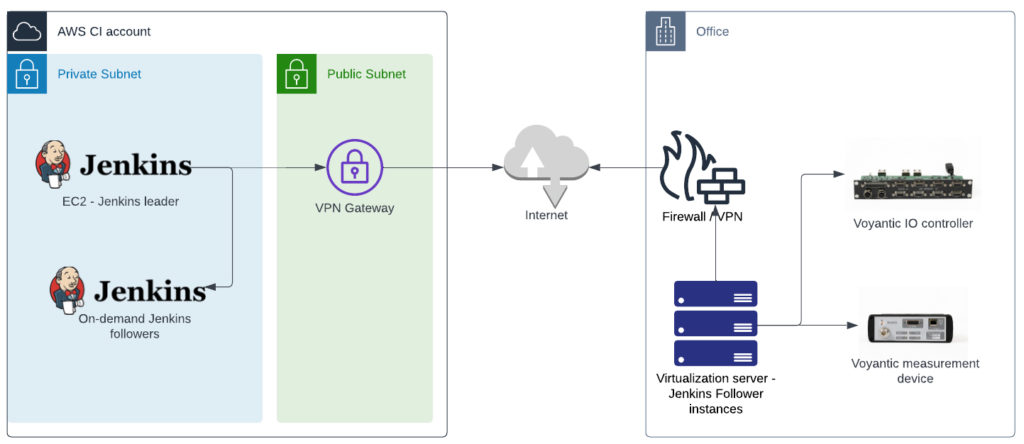
The above diagram depicts the high level CI-system architecture. Jenkins leader is running on a dedicated AWS CI account. The leader is starting on-demand Jenkins followers for build jobs not requiring access to the Voyantic hardware devices. Build jobs using Voyantic hardware devices are run on the on-premise Jenkins follower. This gives us the ability to test cloud services efficiently with co-located cloud-based followers, as well as embedded software running on our own HW devices connected to our on-premise servers.
All continuous integration pipelines are fully automated. Once the developer creates a PR, it will start the Jenkins pipeline to build the code, run static checks and unit tests, deploy it to its target environment, and run integration tests. After merging the PR to the main branch, the pipeline is started again and the same tests are executed but in addition, E2E tests are run too.
Not to be overly rosy in this description, this does not apply to all of our git repositories and some are lacking direly behind but all new software is following this model and we are relentlessly working to add all other SW components under active development to this model.
The last key aspect of test automation is reliability. Regular failures due to badly designed tests will cause failing test jobs to be ignored, leading to gradual test deterioration. This matters a great deal, especially on the e2e test phase – since e2e tests are not gating the PR merging to the main line, it makes it easier for developers to ignore. Rather test less and more reliably, than have complex brittle tests.
Summary
After reading the above “Wikipedia” page of the testing and falling asleep, here are a few key points to take home.
- Use the test pyramid as a guideline to define and understand your test levels on CI
- Aim to have a fast feedback cycle
- Simple reliable tests over complex but brittle ones
- Provide infrastructure to support the continuous integration with your own devices
- Be “lazy” and automate all repetitive tasks